
Latxa: Suite de Evaluación y Modelos de Lenguaje Abiertos para el Euskera
Nos complace presentar un nuevo paso en nuestros esfuerzos para la construcción de modelos de lenguaje de gran tamaño (MLG) y conjuntos de evaluación que posibiliten la investigación reproducible sobre el desarrollo de MLG para el euskera y otros idiomas con recursos limitados, tal y como se describe en un nuevo artículo (https://arxiv.org/abs/2403.20266).
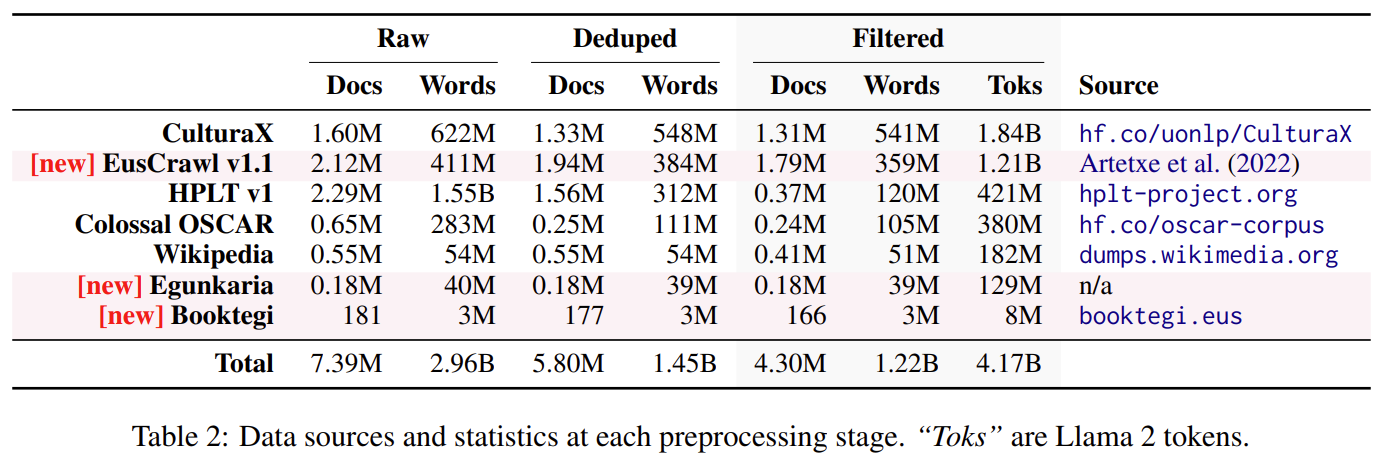
El artículo presenta una nueva versión de Latxa, una familia de modelos de lenguaje de gran tamaño para el euskera que constan desde 7 hasta 70 mil millones de parámetros. Latxa se basa en Llama 2, el cual continuamos pre-entrenando en un nuevo corpus de euskera de 4.3 millones de documentos y 4.2 mil millones de tokens. Este nuevo corpus es el más grande disponible para el euskera (más del doble del tamaño de sus predecesores) y combina varios conjuntos de datos existentes, así como algunos nuevos que publicamos con este trabajo. Al construir nuestro corpus, hemos priorizado la calidad sobre la cantidad, seleccionando fuentes de datos de alta calidad y aplicando un proceso exhaustivo de deduplicación y filtrado.
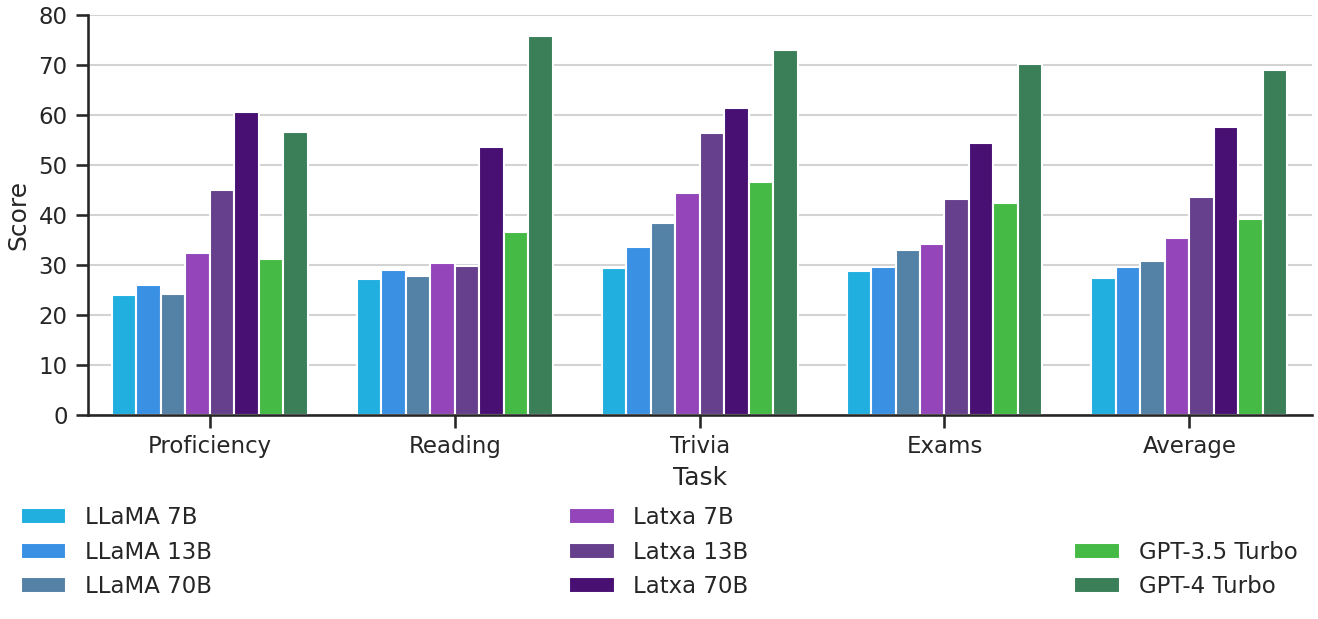
Para abordar la escasez de conjuntos de evaluación de alta calidad para el euskera, también presentamos cuatro nuevos tests de opción múltiple: EusProficiency, que consta de 5,169 preguntas de exámenes oficiales de competencia lingüística; EusReading, que incluye 352 preguntas de comprensión lectora; EusTrivia, que contiene 1,715 preguntas de cultura general en 5 áreas de conocimiento; y EusExams, que comprende 16,774 preguntas de exámenes públicos.
En nuestra extensa evaluación, Latxa supera sustancialmente a todos los modelos abiertos existentes, incluido Llama 2. También supera a GPT-3.5 Turbo en todos los conjuntos de datos que evaluamos. Además, nuestro mejor modelo supera a GPT-4 Turbo en exámenes de competencia lingüística, a pesar de quedar rezagado en comprensión lectora y tareas exigentes en cuanto a conocimiento. Esto sugiere que las capacidades que exhibe un MLG en un idioma dado no están determinadas únicamente por su competencia lingüística en ese idioma en particular, lo que abre las puertas a mejoras adicionales en MLGs con recursos limitados a medida que se disponga de modelos en inglés más sólidos.
La familia de modelos Latxa, así como nuestros nuevos corpus de pre-entrenamiento y conjuntos de datos de evaluación, están disponibles públicamente bajo licencias abiertas en https://github.com/hitz-zentroa/latxa.
En el futuro, planeamos ampliar el conjunto de datos de entrenamiento recopilando contenido de calidad de diversas fuentes en euskera, como editoriales o medios de comunicación, además de construir conjuntos de datos de evaluación para evaluar aspectos como la veracidad o las alucinaciones. También tenemos previsto ajustar Latxa para que sea capaz de seguir instrucciones, lo que debería mejorar las capacidades generales de nuestros modelos.
Este trabajo ha recibido apoyo del Gobierno Vasco, dentro del proyecto IKER-GAITU, y ha sido financiado, dentro del proyecto ILENIA, por el Ministerio para la Transformación Digital y de la Función Pública, así como por el Plan de Recuperación, Transformación y Resiliencia – financiado por la Unión Europea – NextGenerationEU, en el marco del proyecto con referencia 2022/TL22/00215335. El desarrollo del modelo se realizó utilizando servidores GPU propios y los modelos finales fueron entrenados en el supercomputador Leonardo de CINECA, en el marco EuroHPC Joint Undertaking (proyecto EHPC-EXT-2023E01-013).



