
Latxa: Euskarazko Hizkuntza Eredu Irekia eta Ebaluazio Multzoa
Atseginez aurkezten dugu euskararako eta baliabide mugatuak dituzten beste hizkuntzetako hizkuntza-eredu handiak garatzeko ikerketa erreproduzigarria ahalbidetzen duten ebaluazio-eredu eta -multzoen sorkuntzan egindako lana, gure artikulu berrian deskribatzen dugun bezala (https://arxiv.org/abs/2403.20266).
Artikuluan Latxa aurkezten dugu, 7 eta 70 mila milioi parametro bitarteko hizkuntza-eredu handien familia. Latxak Llama 2 du oinarri, zein 4.3 milioi dokumentu eta 4.2 mila milioi token dituen euskara corpus berri batean entrenatzen jarraitu dugun. Corpus berri hau euskararentzat eskuragarri dagoen handiena da (aurrekoen tamaina halako bi baino gehiago), eta existitzen diren hainbat datu multzo eta lan honekin argitaratzen ditugun zenbait datu berri konbinatzen ditu. Gure corpusa eraikitzean, kalitatea kantitatearen gainetik lehenetsi dugu, kalitate handiko datu-iturriak hautatuz eta deduplikazio eta behaketa prozesu sakona aplikatuz.
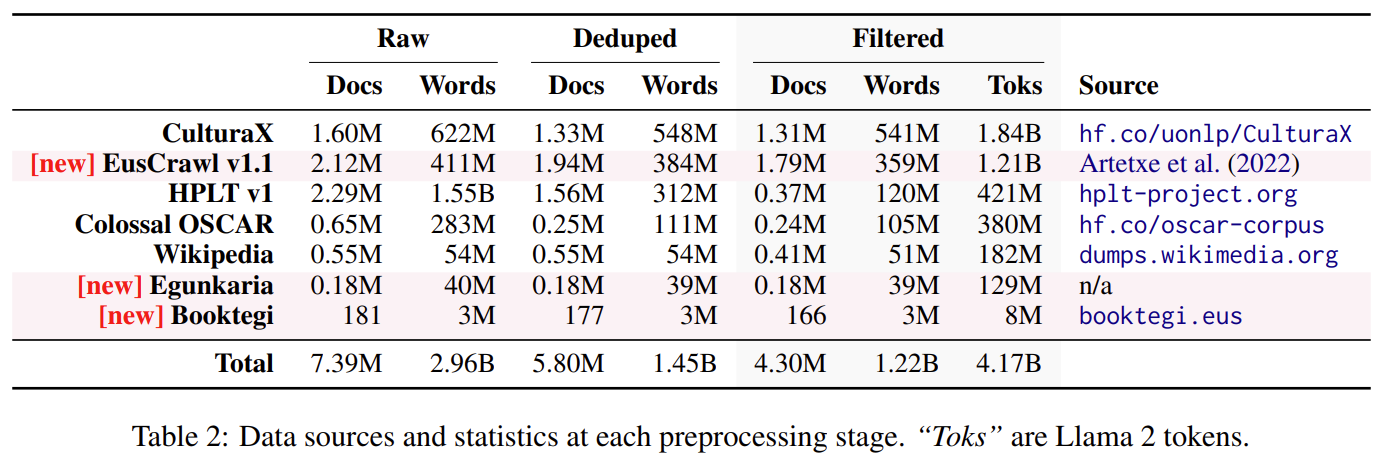
Horrez gain, euskararen kalitate handiko ebaluazio-multzoen urritasunari aurre egiteko, aukera anitzeko lau test berri aurkeztu ditugu: EusProficiency, hizkuntza-gaitasuneko azterketa ofizialetako 5,169 galderaz osatua; EusReading, irakurmeneko 352 galderaz osatua; EusTrivia, 5 ezagutza-arlotako kultura orokorreko 1,715 galderaz osatua; eta EusExams, azterketa publikoetako 16,774 galderaz osatua.
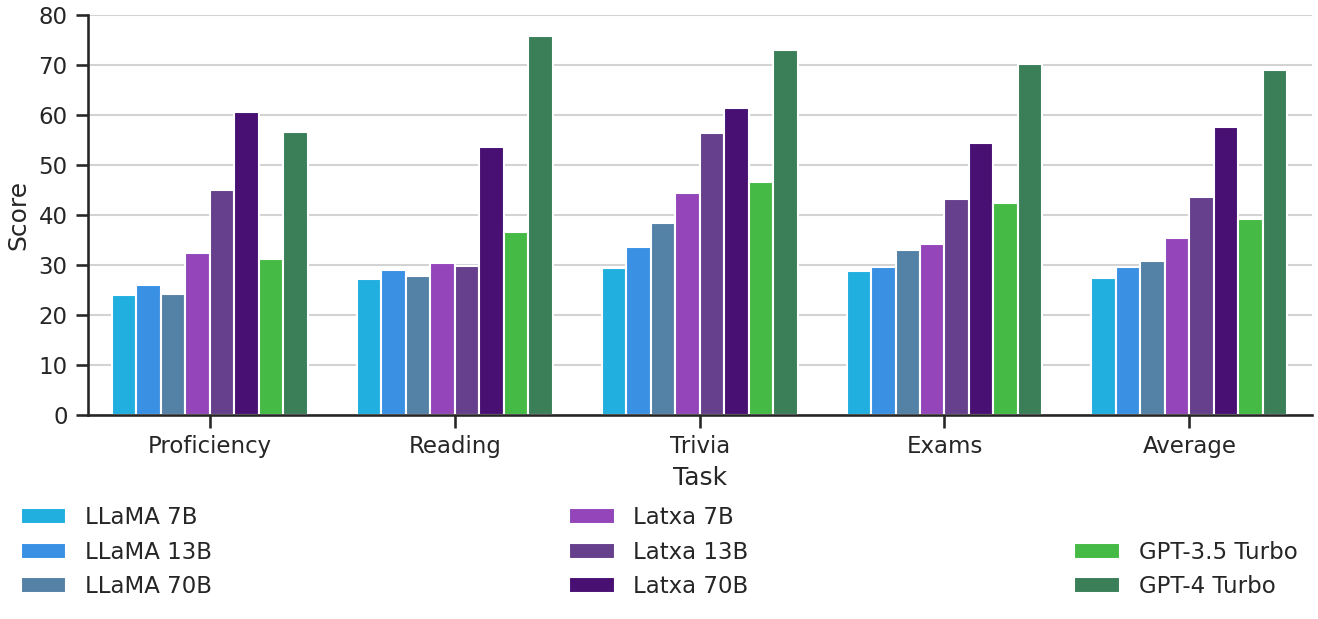
Gure ebaluazioetan, Latxak nabarmen gainditzen ditu existitzen dirn eredu ireki guztiak, Llama 2 barne. Halaber, GPT-3.5 Turbo gainditzen du ebaluatzen ditugun datu-multzo guztietan. Gainera, gure eredurik onenak GPT-4 Turbo gainditzen du hizkuntza-gaitasuneko azterketetan, nahiz eta atzean geratu irakurmenean eta munduaren ezagutza sakona eskatzen duten zereginetan. Horrek iradokitzen du hizkuntza jakin batean hizkuntza-eredu handi batek erakusten dituen gaitasunak ez daudela soilik hizkuntza jakin horretan duen hizkuntza-gaitasunak determinatuta, eta horrek aukera ematen duela baliabide mugatuko hizkuntza-eredu handietan hobekuntza gehigarriak egiteko, ingelesezko eredu sendoagoak eskuragarri izan ahala.
Latxa ereduen familia, baita gure aurreentrenamenduko corpus berriak eta ebaluazio-datuen multzoak ere, eskuragarri daude publikoki https://github.com/hitz-zentroa/latxa helbidean.
Etorkizunean, entrenamenduko datuen multzoa zabaltzeko asmoa dugu, euskarazko hainbat iturritatik, argitaletxeetatik edota komunikabideetatik esaterako, kalitatezko edukia bilduz. Gainera, ebaluazio-datuen multzoak eraiki nahi ditugu egiazkotasuna edo haluzinazioak bezalako alderdiak ebaluatzeko. Latxa doitzeko asmoa ere badugu, jarraibideak betetzeko gai izan dadin, eta horrek gure ereduen gaitasun orokorrak hobetu beharko lituzke.
Lan horrek Eusko Jaurlaritzaren laguntza jaso du, IKER-GAITU proiektuaren barruan, eta, ILENIA proiektuaren barruan, Transformazio Digitalerako eta Funtzio Publikorako Ministerioak finantzatu du, bai eta Ekonomia Suspertzeko eta Eraldatzeko Proiektu Estrategikoak ere – NextGenerationEU Europar Batasunak finantzatua –, 2022/TL22/00215335 erreferentziako proiektuaren esparruan. Ereduaren garapena gure GPU zerbitzariak erabiliz egin dira, eta azken ereduak CINECAko Leonardo superordenagailuan entrenatu dira, EuroHPC Joint Undertaking esparruan (EHPC-EXT-2023E01-013 proiektua).



